Couchbase is excited to announce the release of a new time-series feature as part of Couchbase 7.2. This feature is built on top of the robust Couchbase distributed database architecture, which is designed to scale horizontally as your data grows, all while providing built-in redundancy and high availability. This means that as your business grows and your time series data needs increase, Couchbase can effortlessly expand to meet those needs, making it an ideal solution for businesses of all sizes.
This innovative new technique to manage time series data opens up a whole new world of possibilities for Couchbase users. With the ability to store and analyze vast amounts of time series data using Couchbase SQL++ and SDKs. This allows users to leverage their existing knowledge and infrastructure, making it easy to set up and unlock powerful insights to explore data trends with ease.
Key benefits of time series
Time series data are stored in JSON documents in the Couchbase Multi Model database. It provides the same high performance, advanced caching for fast data retrieval and low latency. Couchbase Query SQL++ and Index service enhance the data retrieval capabilities to allow complex analytical query use cases.
Time Series data support in Couchbase provides these additional benefits:
-
- Efficient storage for large volume of time series data points
- Optimized data structure storage for time stamped data points
- New advanced time series query capabilities
- Low index storage requirement
Examples of time series use cases
Financial Trading – Financial trading relies on the analysis of large amounts of real-time data, including stock prices, currency rates, and commodity prices. Time-series data analysis can help traders identify trends and make informed decisions about buying and selling.
Internet of Things (IoT) Monitoring – IoT devices generate a large amount of time-series data, including temperature readings, energy consumption, and sensor data. This data can be analyzed in real-time to detect anomalies and predict equipment failures before they occur.
Predictive Maintenance – Many industries rely on expensive equipment and machinery, and downtime can be costly. By analyzing time-series data from sensors and other sources, organizations can predict when equipment is likely to fail, and proactively schedule maintenance to minimize downtime and maximize efficiency.
Key features of Couchbase Time Series
You can store time series data in Couchbase, using our SDK/SQL++ to load, and the advanced Analytical query capability with Global Secondary Index to query/analyze the data in the same way as with normal JSON documents.
Storage efficiency
Time series datasets are typically very large, with each data point consisting of attributes, such as timestamp, value(s), granularity and other related information. Efficient storage is critical as it can determine how fast the data can be queried for analysis.
Couchbase time series uses two specifications to improve storage efficiency.
The use of arrays for data points – By its very nature, time series data are a series of data points. These data points share a common structure, e.g., time and values, or any other attributes that are associated with the time when the data point was collected.
Using an array to store a set of the data points for a given range can greatly reduce the storage cost, compared to having to store each individual data point as a separate document in the database.
The use of array position – Also note that data point array elements do not have an associated field name, but instead it relies on the position of the element in the array. In this example, the three elements in the array are: the observation date, the opening value, and the closing value of the stock.
|
1 2 3 4 |
docid: "stock:XYZ:d1" { "ts_data": [ [1672531200000, 92.08, 95.62],[1672531201000, 95.62, 99.25],..] } |
Use EPOCH time – Epoch time is used instead of ISO date string in order to reduce the size of each data point, and improve processing time.
|
1 2 3 4 5 6 7 |
docid: "stock:XYZ:d1" { "ts_data": [ [1672531200000, 92.08, 95.62],[1672531201000, 95.62, 99.25],..] "ts_start": 1672531200000 /* dstart and dend denote the */ "ts_end": 1672617599999,/* time range of all data points in ts_data */ "ticker": "XYZ" } |
Optimized query with a new _timeseries function
Couchbase Time Series feature includes a new _timeseries function. The function serves several purposes:
-
- It dynamically generates the time series objects from the ts_data array of arrays
- It efficiently streams the results when it is used with UNNEST, optimizes response time and memory usage
- It can automatically generate the timestamp for each data point when the ts_interval parameter is used
- It supports more advanced time series use cases for irregular time series data points interval, such as instead of a multiple sets of data points per timestamp
Please refer to the Couchbase time series documentation for more detail.
Optimized index storage
Due to the way Couchbase stores time series data, with each data point stored as an element in an array within a JSON document, we can optimize our database indexing strategy. Specifically, since each document contains both the start and end time of all the data points in the array, we can create a single index definition for each document. This means that even for large time series data sets with millions of data points, we can store the data in just a few documents rather than one document per data point.
For example, a time series data set with 1 million data points can be stored in just 1,000 documents, assuming that each ts_data array can store up to 1,000 data elements and the document size remains below the 20MB Couchbase JSON document limit. This not only reduces the number of documents needed to store the data, but it also leads to smaller index sizes, improving database performance and reducing disk space requirements.
In short, by taking advantage of Couchbase’s ability to store time series data as arrays within JSON documents, we can optimize our indexing strategy to significantly reduce the number of documents needed and reduce the index size, resulting in faster query performance and more efficient use of storage resources.
|
1 |
CREATE INDEX ix1 ON docs(ticker, ts_end, ts_start); |
Data Retention
Time Series documents are stored as standard JSON documents in Couchbase. So the same Time-To-Live (TTL) can be set during the data load process.
|
1 2 3 4 5 |
/* The document will be automatically removed in 30 days */ INSERT INTO coll1 (KEY, VALUE) VALUES ("stock:XYZ:d1", {"ticker":"XYZ",..}, {"expiration":60*60*24*30}); |
Example walkthrough
So let’s walk through the process of loading an actual stock price data set into Couchbase using the time series data model as defined by the feature.
As I have described above, the Couchbase time series feature requires the JSON document in this specific format:
|
1 2 3 4 5 6 7 |
docid: "stock:XYZ:d1" { "ts_data": [ [1672531200000, 92.08, 95.62],[1672531201000, 95.62, 99.25],..] "ts_start": 1672531200000 /* dstart and dend denote the */ "ts_end": 1672617599999,/* time range of all data points in ts_data */ "ticker": "XYZ" } |
Follow the steps below if you need to convert your own time series data into the above format.
The data set used here is for the XYZ Inc stock price for 2013-2015.
XYZ_data.csv
|
1 2 3 4 |
date,open,high,low,close,volume,Name 2013-02-08,27.285,27.595,27.24,27.295,5100734,XYZ 2013-02-11,27.64,27.95,27.365,27.61,8916290,XYZ 2013-02-12,27.45,27.605,27.395,27.545,3866508,XYZ |
Migrate Data into Couchbase time series data structure
- Load the CSV file into a Couchbase collection:
|
1 |
cbimport csv --infer-types -c http://<cluster>:8091 -u <login> -p <password> -d 'file://XYZ_data.csv' -b 'ts' --scope-collection-exp "s1.c1" -g "#UUID#" |
The import will create a JSON document in collection c1 for each data point.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
{ "c1": { "Name": "XYZ", "close": 55.99, "date": "2016-05-25T00:00:00.000Z", "high": 56.69, "low": 55.7699, "open": 56.47, "volume": 9921707 } }, { "c1": { "Name": "XYZ", "close": 31.075, "date": "2013-06-11T00:00:00.000Z", "high": 31.47, "low": 30.985, "open": 31.15, "volume": 5540312 } }, … |
2. Use SQL++ to transform the collection c1 into the time series data structure, then insert into the collection c3:
|
1 2 3 4 5 6 7 8 9 |
INSERT INTO ts.s1.c3 (KEY _k, VALUE _v) SELECT "stock:XYZ:2013" _k, {"ticker": a.Name , "ts_start" : MIN(STR_TO_MILLIS(a.date)), "ts_end" : MAX(STR_TO_MILLIS(a.date)), "ts_data" : ARRAY_AGG([STR_TO_MILLIS(a.date), a.close]) } _v FROM ts.s1.c1 a WHERE a.date BETWEEN "2013-01-01" AND "2013-12-31" GROUP BY a.Name; |
The SQL++ performs an INSERT SELECT and creates a single document with the structure required for Couchbase time series processing. Note that the ts_data array contains the entire 2013 daily closing price data points.
3. Repeat the INSERT/SELECT for 2014 and 2015.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
[ { "id": "stock:XYZ:2013", "ticker": "XYZ", "ts_start": 1387497600000, "ts_end": 1365465600000, "ts_data": [ [ 1387497600000, 38.67 ], [ 1380585600000, 36.21 ], ...] }, { "id": "stock:XYZ:2014", "ticker": "XYZ", "ts_start": 1413331200000, "ts_end": 1402444800000, "ts_data": [ [ 1413331200000, 42.59 ], [ 1399507200000, 36.525], ...] }, { "id": "stock:XYZ:2015", "ticker": "XYZ", "ts_start": 1444780800000, "ts_end": 1436313600000, "ts_data": [ [ 1444780800000, 62.92 ], [ 1421280000000, 46.405], ...] } ] |
Data Ingestion Strategies
There are several scenarios that you may have for incremental loading of your Time Series JSON documents.
-
- Adding a range of data points as a new JSON document – For this scenario you can use the above SQL++ INSERT. You just need to ensure that the data points ranges do not overlap existing documents.
- Adding a range of data points to an existing JSON document – Here you have two options:
- Replace the entire document using UPSERT/SELECT as in the INSERT/SELECT
- Use Couchbase SDK to append only the new item data points
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// Initialize the Couchbase cluster and bucket objects Cluster cluster = CouchbaseCluster.create("<cluster>"); Bucket bucket = cluster.openBucket("<your_bucket>"); // Specify the document ID and the sub-document path to update String docId = "<doc_id>"; // eg. "stock:XYZ:2015" String path = "a.ts_data[-1]"; // -1 specifies the last element of the array // Create a JSON object representing the new array element to add JsonObject newElement = JsonObject.create() .put("0", "2015-12-31") .put("1", 300); // Use the sub-document API to update the array JsonDocument doc = bucket.get(docId); if (doc != null) { bucket.mutateIn(docId) .arrayAppend(path, newElement) .execute(); } |
Query the time series data
Before querying the data, you should create an index. Although this is not absolutely needed as we only have a few documents, even though each document consists of the entire year of the daily stock price.
|
1 |
CREATE INDEX ix1 ON c3(ticker, ts_end, ts_start); |
Next we define the range of data that we want the query to run on. Here we define an array with two elements, the start and end epoch time for 2013-01-01 and 2015-12-31.
|
1 |
\set -$ts_ranges [1682947800000,1685563200000]; |
View the time series data points
Use the _timeseries function as described above:
|
1 2 3 |
SELECT t.* FROM c3 AS d UNNEST _timeseries(d, {"ts_ranges":$ts_ranges}) AS t WHERE d.ticker = 'XYZ' AND (d.ts_start <= $ts_ranges[1] AND d.ts_end >= $ts_ranges[0]); |
Results:
|
1 2 3 4 5 6 |
[ { "_t": 1413331200000, "_v0": 42.59 }, { "_t": 1399507200000, "_v0": 36.525}, { "_t": 1392854400000, "_v0": 37.79 }, { "_t": 1395100800000, "_v0": 39.82 }, { "_t": 1410307200000, "_v0": 41.235}, … ] |
View the time series data with SQL++ Window function
Now that we can access the entire data set, we can use Couchbase SQL++ windows function to run a few advanced aggregation functions. This query returns the daily average for the stock, as well as a 7 day moving average.
|
Results:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
[ { "day": "2014-01-02T00:00:00Z", "dayavg": 39.12, "sevendaymovavg": 39.12 }, { "day": "2014-01-03T00:00:00Z", "dayavg": 39.015, "sevendaymovavg": 39.067499999999995 }, { "day": "2014-01-06T00:00:00Z", "dayavg": 38.715, "sevendaymovavg": 38.949999999999996 }, { "day": "2014-01-07T00:00:00Z", "dayavg": 38.745, "sevendaymovavg": 38.89875 }, { "day": "2014-01-08T00:00:00Z", "dayavg": 38.545, "sevendaymovavg": 38.827999999999996 }, .. ] |
Use SQL++ charting on time series data
In this example, we use the Couchbase Time Series feature and its Charting capability to track a popular trading strategy by tracking fast (5 day) moving averages against slow (30 day) moving averages.
|
1 2 3 4 5 6 7 8 9 |
SELECT MILLIS_TO_TZ(day*86400000,"UTC") AS day, dayavg , AVG(dayavg) OVER (ORDER BY day ROWS 5 PRECEDING) AS fma, AVG(dayavg) OVER (ORDER BY day ROWS 30 PRECEDING) AS sma FROM ts.s1.c3 AS d UNNEST _timeseries(d, {"ts_ranges":$ts_ranges}) AS t WHERE d.ticker = 'XYZ' <span style="font-weight: 400"> AND (d.ts_start <= $ts_ranges[</span><span style="font-weight: 400">1</span><span style="font-weight: 400">] AND d.ts_end >= $ts_ranges[</span><span style="font-weight: 400">0</span><span style="font-weight: 400">])</span> GROUP BY IDIV(t._t,86400000) AS day LETTING dayavg = AVG(t._v0); |
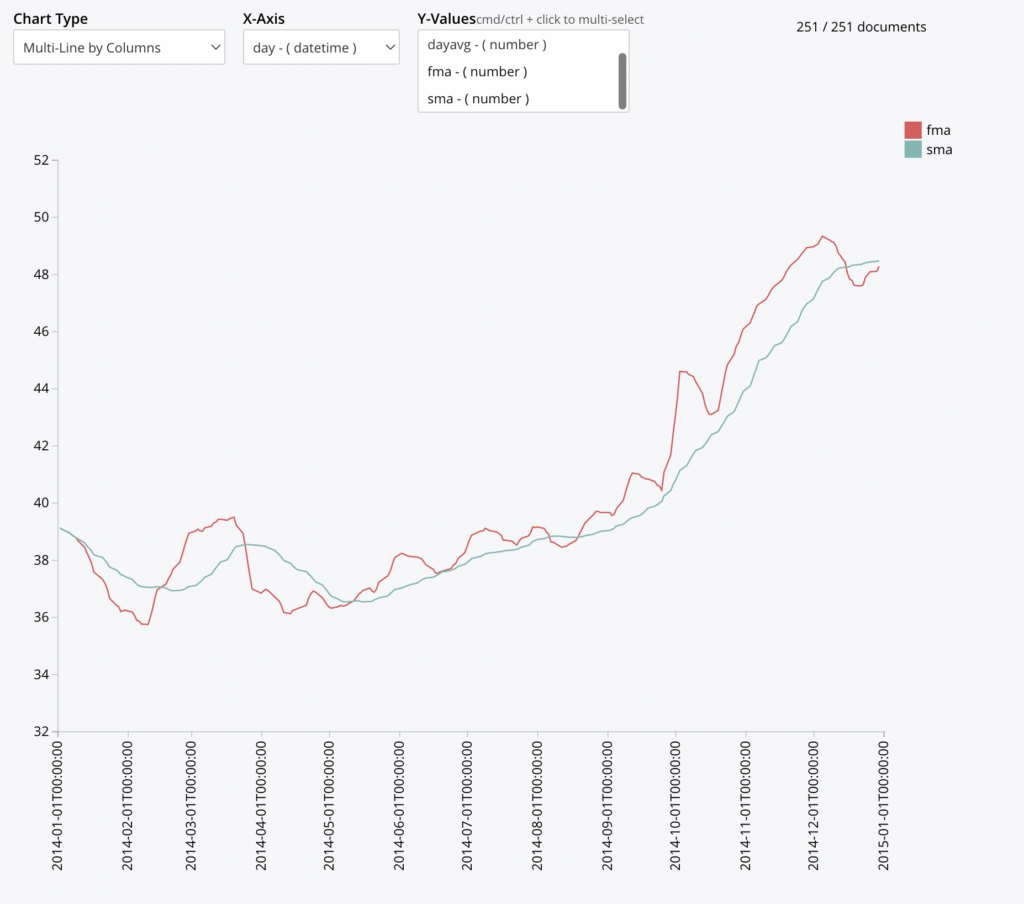
The idea behind this strategy is to identify when the short term trend (FMA) is crossing above or below the long term (SMA). When the FMA crossed the SMA, it is considered a buy signal, and conversely a sell signal when the FMA crossed below the SMA.
Use SQL++ Common Table Expression with time series data
This analysis calculates the Relative Strength Index, i.e., the speed and change of the stock price movements to identify when a stock is overbought or sold. An RSI value > 70 may indicate that the stock is overbought and due for correction. Conversely, when the RSI < 30, it may indicate that the stock is oversold and due for a rebound.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
WITH price_change AS ( SELECT t._t as date, t._v0 AS price, LAG(t._v0, 1) OVER (ORDER BY t._t) AS prev_price, ROW_NUMBER() OVER (ORDER BY t._t) AS rn FROM ts.s1.c3 AS d UNNEST _timeseries(d, {"ts_ranges":$ts_ranges}) AS t WHERE d.ticker = 'XYZ' AND ( $ts_ranges[0] BETWEEN d.ts_start AND d.ts_end OR (d.ts_start BETWEEN $ts_ranges[0] AND $ts_ranges[1] AND d.ts_end BETWEEN $ts_ranges[0] AND $ts_ranges[1] ) OR $ts_ranges[1] BETWEEN d.ts_start AND d.ts_end ) ), gain_loss AS ( SELECT pc.date, pc.price, pc.prev_price, CASE WHEN pc.price > pc.prev_price THEN pc.price - pc.prev_price ELSE 0 END AS gain, CASE WHEN pc.price < pc.prev_price THEN pc.prev_price - pc.price ELSE 0 END AS loss, pc.rn FROM price_change pc ), avg_gain_loss AS ( SELECT gl.date, AVG(gl.gain) OVER (ORDER BY gl.rn ROWS BETWEEN 13 PRECEDING AND CURRENT ROW) AS avg_gain, AVG(gl.loss) OVER (ORDER BY gl.rn ROWS BETWEEN 13 PRECEDING AND CURRENT ROW) AS avg_loss, gl.rn FROM gain_loss gl ), rsi AS ( SELECT agl.date, 100 - (100 / (1 + (agl.avg_gain / agl.avg_loss))) AS rsi_val FROM avg_gain_loss agl WHERE agl.rn >= 14 ), buy_sell_signals AS ( SELECT rsi.date, rsi.rsi_val, CASE WHEN rsi.rsi_val < 30 THEN 'buy' WHEN rsi.rsi_val > 70 THEN 'sell' END AS signal FROM rsi ) SELECT * FROM buy_sell_signals bss WHERE bss.signal IS NOT NULL; |
Results:
|
||
Key Takeaways
Data Storage – The overall data storage for the Couchbase time series will depend how many data points you choose to pack into the array. If analysis is by hour, day, month, then pack the data points according to the period. Note that the storage can also be further reduced if a regular time series is used where the time element in the time series can be derived, and thus does not require storing of the epoch time element.
Data Element and Data Retention with TTL – The maximum size of the JSON document in Couchbase is 20MB. While this could mean you can pack a large number of data points into the time series array, you should also be aware that the Time To Live setting is at the document level, and not the array element level.
Data Ingestion – Application is responsible for the data ingestion strategy. How to pack the time series data point into the arrays, and array size. Meaning it has to decide whether to append to an existing document, or start a new one.
To learn more, see the Couchbase time series documentation.